����13�N�x �H�� ��{���Z�p�Ҏ����ߌ���
|
��P�`��T�܂ł͕K�{���ł��B�S����Ă��������B
|
|
��P
���ߌ�Ɋւ��鎟�̋L�q��ǂ�ŁC�ݖ�ɓ�����B
���Ɏ����`���̖��ߌꂪ����B

(1)�@���ߌ�� 2 ��i32 �r�b�g�j�� 1 ���߂�\���B1 ��� 16 �r�b�g�ł���B
(2)�@�e���̈Ӗ��́C���̂Ƃ���ł���B
 �@���ߕ��i�r�b�g�ԍ� 0 �` 7�j �@���ߕ��i�r�b�g�ԍ� 0 �` 7�j
���߃R�[�h �� ���i�[����Ă���B
 �@���W�X�^���i�r�b�g�ԍ� 8 �` 11�j �@���W�X�^���i�r�b�g�ԍ� 8 �` 11�j
���W�X�^�ԍ� �� ���i�[����Ă���i0������15�j�B
 �@�C�����i�r�b�g�ԍ� 12 �` 15�j �@�C�����i�r�b�g�ԍ� 12 �` 15�j
�A�h���X���̏C������������ �� ���i�[����Ă���i0������15�j�B
 �@�A�h���X���i�r�b�g�ԍ� 16 �` 31�j �@�A�h���X���i�r�b�g�ԍ� 16 �` 31�j
��L���̌�̃A�h���X �� ���i�[����Ă���B
(3)�@�����A�h���X�́C�� �ɑΉ����āC���̂Ƃ���ł���B
|
�� �̒l
|
�����A�h���X
|
|
0
|
��
|
|
1 �` 15
|
���W�X�^ �� �̓��e�{��
|
(4)�@16 �i���ŕ\�����߃R�[�h�̈ꕔ�Ƃ��̈Ӗ������Ɏ����B
|
���߃R�[�h
|
���߃R�[�h�̈Ӗ�
|
|
�c
|
�c
|
|
4A
|
�����A�h���X�����W�X�^ �� �ɐݒ肷��B |
|
4B
|
�����A�h���X���w����̓��e�����W�X�^ �� �ɐݒ肷��B |
|
�c
|
�c
|
�ݖ��@���̋L�q����  �ɓ���鐳�����������C�Q�̒�����I�ׁB
�ɓ���鐳�����������C�Q�̒�����I�ׁB
���̓�̖��ߌꂪ����B�����̖��ߌ�̎��s���O�̊e���W�X�^�y�ю�L���̓��e�́C���ꂼ��} 1 �y�ѐ} 2 �Ɏ����Ƃ���Ƃ���B�e���e�́C16
�i���ŕ\���Ă���B
���ߌ� 1�@�@�@4A3001A0
���ߌ� 2�@�@�@4B450003
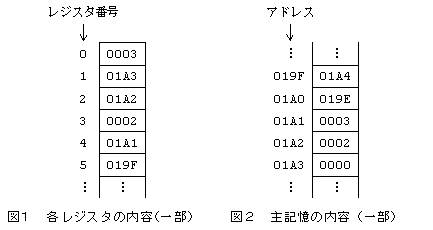
(1)�@���ߌ� 1 �� �� �̒l�́C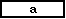 �ł���B �ł���B
(2)�@���ߌ� 1 �����s����ƁC���W�X�^  �� ��
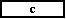 ���ݒ肳���B ���ݒ肳���B
(3)�@���ߌ� 2 �����s����ƁC���W�X�^ 4 ��  ���ݒ肳���B ���ݒ肳���B
a�Cb �Ɋւ���Q
�A�@0�@�@�@�@�C�@1�@�@�@�@�E�@3�@�@�@�@�G�@4
�I�@5�@�@�@�@�J�@A�@�@�@�@�L�@B
c�Cd �Ɋւ���Q
�A�@0000�@�@�@�@�C�@0002�@�@�@�@�E�@0003�@�@�@�@�G�@019E
�I�@019F�@�@�@�@�J�@01A0�@�@�@�@�L�@01A1�@�@�@�@�N�@01A2
�P�@01A3�@�@�@�@�R�@01A4�@�@
�@ |
|
| �@ |
|
��Q
�@���̃v���O�����̐����C�[������̋L�q�`���̐����y�уv���O������ǂ�ŁC�ݖ�ɓ�����B
�k�v���O�����̐����l
�����l���C�w�肳�ꂽ�����ɏ]���� 10 �i�̐�����ɕϊ����镛�v���O�����ł���B
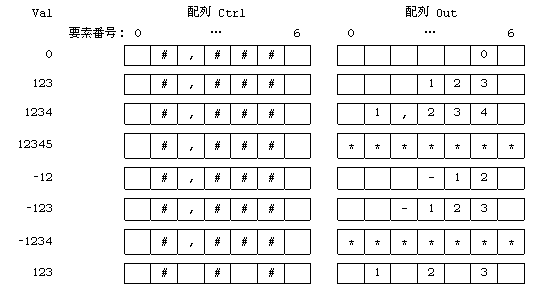
(1)�@���v���O���� Format �́C�z�� Ctrl �Ɋi�[����Ă��鏑�������ɏ]���āC�ϐ� Val �Ɋi�[����Ă��鐮���l�� 10
�i�̐�����ɕϊ����C�z�� Out �Ɋi�[����B
Format �̈����̎d�l��\ 1 �Ɏ����B
�\�P�@�����̎d�l
|
�ϐ���
|
���́^�o��
|
�Ӗ�
|
| Val |
����
|
�ϊ��Ώۂ̐����l |
| Ctrl[] |
����
|
�����������i�[����Ă��镶���^�̔z�� |
| Out[] |
�o��
|
�ϊ����ʂ��i�[���镶���^�̔z��
�v�f���͔z�� Ctrl �Ɠ���
|
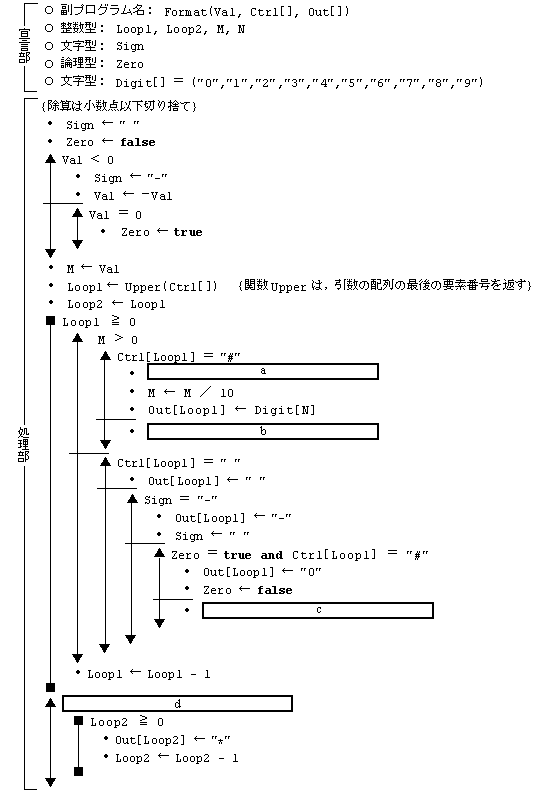
(2)�@�z�� Ctrl �̊e�v�f�ɂ́C�\ 2 �Ɏ������������������i�[����Ă���B Format �́C�z�� Ctrl
�̍Ō�̗v�f����ŏ��Ɍ������āC�e���������̈Ӗ����鏈�����s���C�z�� Out �̑Ή�����ʒu�Ɍ��ʂ��i�[����B
�\�Q�@���������̎�ނƈӖ�
|
��������
|
�Ӗ�
|
|
�g # �h
|
10 �i������ 1 �������͕��������i�[����B �������C�����l�̕ϊ����I����Ă���ꍇ�́C�������i�[����B |
|
�g , �h
|
�������̃R���}���͕��������i�[����B �������C�����l�̕ϊ����I����Ă���ꍇ�́C�������i�[����B |
|
�g�@�h
|
�������i�[����B |
(3)�@�ϐ� Val �̐����l���������ϊ��ł��Ȃ��ꍇ�́C�z�� Out �̑S�v�f�Ɂg*�h���i�[����B
(4)�@�z�� Ctrl �ɂ́C���Ȃ��Ƃ���́g#�h���܂܂��B
��F
�k�[������̋L�q�`���̐����l

�k�v���O�����l
�ݖ��@�v���O��������
�ɓ���鐳�����������C�Q�̒�����I�ׁB
a �Ɋւ���Q
�A�@N �� M �| (M * 10)�@�@�@�@�@�@�@�@�C�@N �� M �| (M �^ 10)
�E�@N �� M �| ((M * 10) �^ 10)�@�@�@�@�G�@N �� M �| ((M �^ 10) * 10)
b�Cc �Ɋւ���Q
�A�@Out[Loop1] �� Ctrl[Loop1]�@�@�@�@�C�@Out[Loop1] �� Digit[N]
�E�@Out[Loop1] �� " "�@�@�@�@�@�@�@�@�G�@Out[Loop1] �� "-"
�I�@Out[Loop1] �� "0"�@�@�@�@�@�@�@�@�J�@Out[Loop1] �� ","
d �Ɋւ���Q
�A�@M �� 0�@�@�@�@�@�@�@�@�@�@�@�@�C�@M �� 0 and Sign �� "-"
�E�@M �� 0 or Sign �� "-"�@�@�@�@�G�@M �� 0 and Zero �� false
�I�@M �� 0 or Zero �� false
|
|
| �@ |
|
��R�@
�@�g�����U�N�V�����������\�Ɋւ��鎟�̋L�q��ǂ�ŁC�ݖ�ɓ�����B
�}�Ɏ����悤�� 1 �� CPU �y�� 2 ��̃f�B�X�N���u����\�������T�[�o������B�e�f�B�X�N�ɂ́C�}�̂悤�ɂ��ꂼ��f�[�^�x�[�X DB1
�ƃf�[�^�x�[�X DB2
���i�[����Ă���B���̃T�[�o�ɂ����āC�e�f�B�X�N�ňقȂ�g�����U�N�V���������ꂼ��Ɨ��ɏ������邱�Ƃ��ł���B���̃g�����U�N�V���������̓��e�͂����Ƃ���C1
�g�����U�N�V����������̃V�X�e�������̕��ώg�p���Ԃ̓���́C�\�̂Ƃ���ł������B
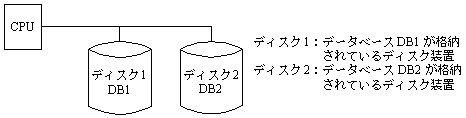
�}�@�T�[�o�̍\��
�\�@1�g�����U�N�V����������̃V�X�e�������̕��ώg�p����
|
�V�X�e������
|
1 �g�����U�N�V����������̕��ώg�p����
|
|
CPU
|
20 �~���b
|
|
�f�B�X�N 1
|
80 �~���b
|
|
�f�B�X�N 2
|
40 �~���b
|
�T�[�o�ғ����̂��鎞�_�ɂ����āC1 �b�Ԃɂ��̃T�[�o����������g�����U�N�V�������������̃T�[�o�� TPS�iTransaction Per
Second�j�ƌĂԁB���̂Ƃ��C�T�[�o�� TPS�C����V�X�e�������̎g�p���C�y�� 1
�g�����U�N�V����������̂��̃V�X�e�������̕��ώg�p���ԁi�ȉ��C���ώg�p���ԂƌĂԁj�̊W�́C���̂Ƃ���ł���B
�g�p�� �� TPS �~ ���ώg�p���ԁ@�c�c�c�@
�Ⴆ�C����V�X�e�������̕��ώg�p���Ԃ� 50 �~���b�ł����āC���̎g�p����
80�� �ł���Ƃ��C�T�[�o�� TPS �͎����Ōv�Z�ł���B
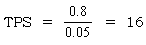
�ݖ��@���̋L�q����
�ɓ���鐳�����������C�Q�̒�����I�ׁB
(1)�@�}�Ŏ����e�V�X�e�������̎g�p���̏���l�� 40�� �Ƃ����ꍇ�C���̃T�[�o�� TPS �̏���l�� �ł���B
(2)�@�e�V�X�e�������̎g�p���̏���l�� 40�� �Ƃ����܂܂ŁC�T�[�o�� TPS �̏���l�� 4 �{�ɂ��邽�߂ɂ́C���Ȃ��Ƃ�
�ɂ��ăf�B�X�N���u�̃A�N�Z�X���Ԃ�Z�k������K�v������B�����ŁC����V�X�e�������� n
�{�ɂ����ꍇ�C�g�����U�N�V���������ɂ����邻�̃V�X�e�������̃A�N�Z�X���Ԃ� 1�^n �ɂȂ���̂Ƃ���B
(3)�@���̃T�[�o�� TPS �� 10 �̂Ƃ��C���̃g�����U�N�V���������̕��ω������Ԃ́C�g�����U�N�V�����������Ԃ̖�
�{�ł���B�����ŁC�e�V�X�e�������̕��ω������Ԃ͎��̂Ƃ���Ƃ��C�g�����U�N�V���������̕��ω������Ԃ͊e�V�X�e�������̕��ω������Ԃ̘a�Ƃ���B

(4)�@�� �y�� ����C�T�[�o�� TPS
���グ�Ă����ƃV�X�e�������̎g�p���͍����Ȃ�C
���Ƃ�������B
a �Ɋւ���Q
�A�@0.005�@�@�@�@�C�@0.01�@�@�@�@�E�@0.02
�G�@5�@�@�@�@�@�@�I�@10�@�@�@�@�@�J�@20
b �Ɋւ���Q
�A�@�f�B�X�N 1 �̑䐔�� 4 ��
�C�@�f�B�X�N 2 �̑䐔�� 4 ��
�E�@�f�B�X�N 1 �̑䐔�� 2 ��C���f�B�X�N 2 �̑䐔�� 2 ��
�G�@�f�B�X�N 1 �̑䐔�� 2 ��C���f�B�X�N 2 �̑䐔�� 4 ��
�I�@�f�B�X�N 1 �̑䐔�� 4 ��C���f�B�X�N 2 �̑䐔�� 2 ��
c �Ɋւ���Q
�A�@0.48�@�@�@�@�C�@0.95�@�@�@�@�E�@1.66
�G�@2.86�@�@�@�@�I�@3.51
d �Ɋւ���Q
�A�@���ω������Ԃ���������@�@�@�@�C�@���ω������Ԃ���������
�E�@���ώg�p���Ԃ���������@�@�@�@�G�@���ώg�p���Ԃ���������
|
|
| �@�@ |
|
��S
�@���̃v���O�����̐����C�[������̋L�q�`���̐����y�уv���O������ǂ�ŁC�ݖ�1�C2 �ɓ�����B
�k�v���O�����̐����l
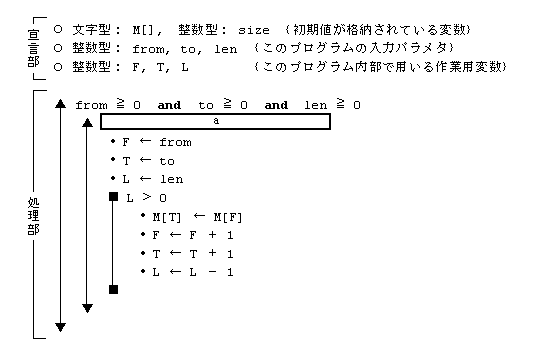
�z�� M �̗v�f�ԍ� from ���� len �̔z��v�f�i����ʌ��̈�ƌĂԁj�̓��e���C�z�� M �̗v�f�ԍ� to ���� len
�̔z��v�f�i����ʐ�̈�ƌĂԁj�֕��ʂ���B
(1)�@�z�� M �̗v�f���� size �ŁCsize �� 0 �ł���B�v�f�ԍ��� 0 ����n�܂�B
(2)�@���ʂ���v�f���� len �ŁClen �� 0 �ł���B
(3)�@�����́C1 �v�f��ǂݏo���Ċi�[���鑀����C�v�f�ԍ��̏����� len ��J��Ԃ��B
(4)�@�����̊T�v���C���Ɏ����B

�k�[������̋L�q�`���̐����l

�k�v���O���� 1�l
| �ݖ�P |
�@���̋L�q����
�ɓ���鐳�����������C�Q�̒�����I�ׁB |
�v���O���� 1 �̑I�������ł́Cfrom�Cto�Clen �̒l�����łȂ����ƁC�y�уv���O�����̏������ɔz�� M
�̓Y���̒l��������Ȃ����Ƃ肵�Ă���B���̂��߂Ɏw�肷�ׂ��������́C �ł���B
���ʌ��̈�ƕ��ʐ�̈�Ƃ��ꕔ�d�����Ă���ƁC�v���O�������s�O�̕��ʌ��̈�̓��e�ƁC�v���O�������s��̕��ʐ�̈�̓��e�Ƃ���v���Ȃ��ꍇ��������B�Ⴆ�C�v���O�������s�O�̕��ʌ��̈�̓��e���C���̂Ƃ��C
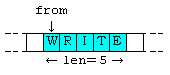
to �̒l��
�Ƃ��ăv���O���������s����ƁC���s��̕��ʐ�̈�̓��e�́C

�ƂȂ�B
��ʂɁC���e�̈�v���ۏł��Ȃ��̂́C���ʐ�Ƃ��Ċi�[���ꂽ�v�f���C��ɕ��ʌ��̗v�f�Ƃ��ēǂݏo�����ꍇ�ł��邩��C �Ƃ��������̂Ƃ��ł���B
a �Ɋւ���Q
�A�@from �� size and to �� size
�C�@from �� size and to �� size andlen �� size
�E�@from�{len �� size and to�{len �� size
�G�@from�{len �� size and to�{len �� size
b �Ɋւ���Q
�A�@from�|1�@�@�@�@�C�@from�{len�|1
�E�@from�{1�@�@�@�@�G�@from�{len�{1
c �Ɋւ���Q
�A�@from �� to and to �� from�{len
�C�@to �� from and from �� to�{len
�E�@from �� to and to �� from�{len
�G�@to �� from and from �� to�{len
|
| �@ |
| �ݖ�Q |
�@���̃v���O���� 2 ����
�ɓ���鐳�����������C�Q�̒�����I�ׁB |
�O�Ɏ������v���O�����̐����ɁC���� (5) �` (7) ��lj����āC���̎d�l�����v���O���� 2 �����B
(5)�@�z�� M �̔z��v�f�́C�Ō������擪�ւƏz���Ă�����̂Ƃ���B���Ȃ킿�C���ʌ��̈�y�ѕ��ʐ�̈�̂�������CM[size�|1] �̒����
M[0] ���������̂Ƃ��āC�������p������B���Ɏ����̂́C���ʌ��̈悪�z���Ă���ꍇ�̗�ł���B

(6)�@���ʂ���v�f�� len �̒l�͈̔͂́C0 �� len �� size �Ƃ���B
(7)�@�v���O�������s�O�̕��ʌ��̈�̓��e�ƁC�v���O�������s��̕��ʐ�̈�̓��e�Ƃ̈�v���ۏł��Ȃ��Ƃ��́C���ʂ������ɃG���[�����v���O�������ĂԁB
�k�v���O���� 2 �l
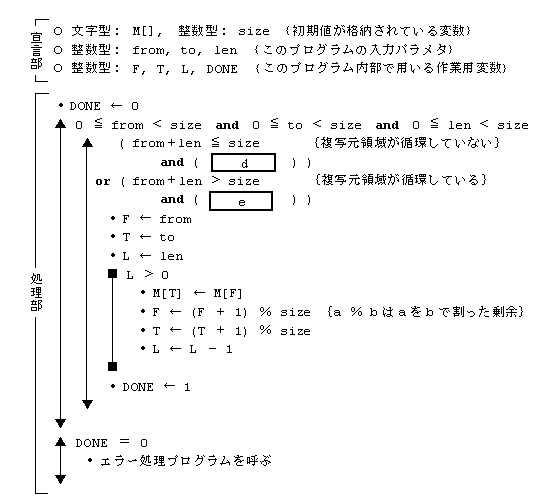
�Q
�A�@from�{len �� to and to �� from
�C�@from�{len �� to or to �� from
�E�@from�{len�|size �� to and to �� from
�G�@from�{len�|size �� to or to �� from
|
|
| �@ |
|
��T
�@�t�@�C���̓ˍ��������Ɋւ��鎟�̋L�q��ǂ�ŁC�ݖ� 1 �` 4 �ɓ�����B
R �Ђ͒ʐM�̔��Ǝ҂ł���B R �Ђ̌ڋq�Ǘ��V�X�e���̊T�v�́C���̂Ƃ���ł���B
(1)�@�L���̎��{�F���� 1 ��C�V���ƃ_�C���N�g���[���iDM�j�ɂ���ď��i�̍L��������B DM
�͉ߋ��ɏ��i���w���������Ƃ̂���ڋq�i�����ڋq�j�ɗX������B
(2)�@���i�w���\���݂̎�t�FDM
�ɓ���������p�̐\���݂͂����i�ȉ��C��p�͂����ƌĂԁj�ɂ�鏤�i�w���\���݂̏ꍇ�́C�����ڋq����̐\���݂Ƃ��ď�������B��p�͂����ɂ́C�ڋq�ԍ����͂��߂Ƃ������炩���߈��Ă���B�V���L�����݂āC��p�͂�����p�����ɏ��i�w���\���݂����Ă����ꍇ�ɂ́C�V�K�ڋq�Ƃ��Čڋq�f�[�^�x�[�X�ɓo�^����B�ڋq�f�[�^�x�[�X�̍X�V�����́C���܂����j���Ɉꊇ���čs���B
R �Ђ̌ڋq�f�[�^�x�[�X�ɂ́C�ڋq�̗X�֔ԍ��C�Z���C�����C�d�b�ԍ��C�ߋ� 1 �N�Ԃ̐\���ݎ��тȂǂ��L�^����Ă���B (2)
�ŏq�ׂ��V�K�ڋq���C�ڋq�f�[�^�x�[�X�ɓo�^����ہC�ڋq�J�E���^���g���Čڋq�ԍ���t�^����B
�ڋq�f�[�^�x�[�X�ɓo�^����Ă���ڋq���C��p�͂�����p�����ɐ\������ł����ꍇ�́C�V�K�ڋq�Ƃ��Čڋq�f�[�^�x�[�X�ɓo�^����Ă��܂��B���̌��ʁC����ڋq���ڋq�f�[�^�x�[�X��ɕʌڋq�Ƃ��ēo�^����鎖��i�d���ڋq�j����������B���̂Ƃ��C�Z���\�L�̏ȗ��̎d���Ȃǂ��قȂ��Ă���ꍇ������B
�ڋq�̏d���� DM �R�X�g�̖��ʂɂ��Ȃ�̂ŁC�d���ڋq�̖��i����l�̓o�^�f�[�^���܂Ƃ߂邱�Ɓj���s�����Ƃɂ����B
�����͖����C���Ƃōs�����Ƃɂ����B���̂��߂̎����Ƃ��āC�ڋq�f�[�^�x�[�X�̓��e��l�X�ȏ����i�Ⴆ�C�������C�Z�����C�d�b�ԍ����Ȃǁj�Ő��Ċe��̃��X�g���o�͂����B�����̃��X�g�����ƂɁC����ڋq���ǂ����̔�������C�d���ڋq�̃f�[�^���܂Ƃ߂��B�������C���݂̌ڋq�f�[�^�x�[�X�X�V�����̂܂܂ł́C���Ԃ��o�߂���ƁC�Ăьڋq�̏d�����������Ă��܂��B
�����ŁC���L�[�y�і��p�ڋq�}�X�^�t�@�C����p�����C�} 1 �̖��L�[�쐬�y�ьڋq�f�[�^�x�[�X�X�V�����Ɛ} 2
�̖��p�ڋq�}�X�^�t�@�C���X�V�����ŁC�d���̔����h�~���ώ@���邱�Ƃɂ����B
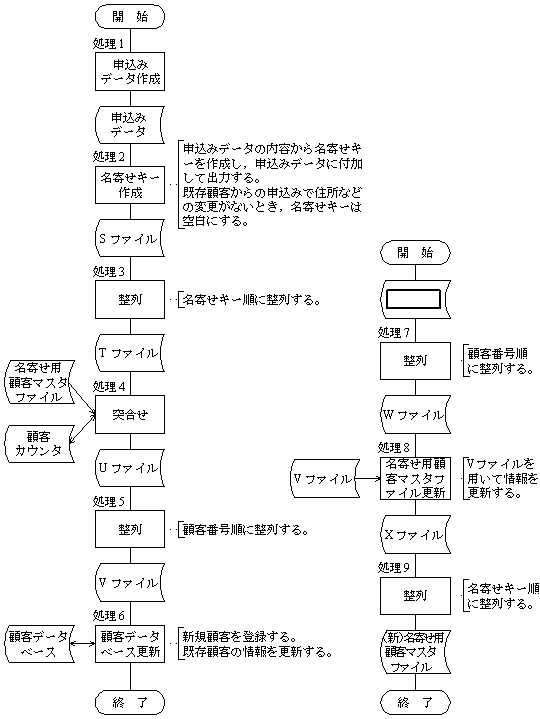
�}�P�@���L�[�쐬�y�с@�@�@�@�@�@�@�}�Q�@���p�ڋq�}�X�^�t�@�C��
�@�@�@�@�ڋq�f�[�^�x�[�X�X�V�����@�@�@�@�@�@�@
�X�V����
���L�[�Ƃ́C�X�֔ԍ��C�Z���C�����y�ѓd�b�ԍ������̌`���ɕϊ��������̂ł���C�ˍ��������Ɏg�p����B���Ƃł̖��̌o������ɁC�Ⴆ�C�g�����s�`��Ճm��꒚��
16 �� 4 ���h�Ɓg�`��Ճm�� 1 �| 16 �| 4�h��Z���ƌ��Ȃ����߂̍H�v���C���L�[�ɂ͂Ȃ���Ă���B
���p�ڋq�}�X�^�t�@�C���́C�ڋq�f�[�^�x�[�X�̓��e�ɖ��L�[��t�����C���L�[�̏��Ԃɕ��בւ������̂ł���B
�\���݃f�[�^�i�}
3�j���쐬����Ƃ��C��p�͂����ɂ��\���݂̏ꍇ�ɂ����ڋq�ԍ�����͂���B����ȊO�̏ꍇ�́C�ɂ���B�܂��C��p�͂����̏ꍇ�C�Z���Ȃǂ̕ύX�L��������Ƃ������C�\���݃f�[�^�ɗX�֔ԍ��C�Z���C�����y�ѓd�b�ԍ������ׂē��͂���B
|
�ڋq�ԍ�
|
�X�֔ԍ�
|
�Z��
|
����
|
�d�b�ԍ�
|
�\����
|
���l
|
�\�����e
|
|
���i�R�[�h
|
����
|
�c
|
���i�R�[�h
|
����
|
�}�R�@�\���݃f�[�^�̗l��
| �ݖ�P |
�@�} 1 �̏��� 4 �ɂ��āCT �t�@�C���̃f�[�^�� 1 �����ǂނƂ��̏����Ƃ��āC �ɓ���鐳�����������C�Q�̒�����I�ׁB |
(1)�@�ڋq�ԍ��̂���f�[�^�́C ����B
(2)�@�ڋq�ԍ����Ȃ��C��v���閼�L�[�����p�ڋq�}�X�^�t�@�C���ɑ��݂����B���̏ꍇ ���C ����B
(3)�@�ڋq�ԍ����Ȃ��C��v���閼�L�[�����p�ڋq�}�X�^�t�@�C���ɑ��݂��Ȃ������B���̏ꍇ ���C�ύX�����f�[�^�� U �t�@�C���ɏo�͂���B
�Q
�A�@T �t�@�C���̌ڋq�ԍ����擾
�C�@T �t�@�C���̗X�֔ԍ��C�Z���C�����y�ѓd�b�ԍ����擾
�E�@�ڋq�J�E���^��p���āC�V���Ȍڋq�ԍ����擾
�G�@���̂܂� U �t�@�C���ɏo��
�I�@���L�[���č쐬
�J�@���p�ڋq�}�X�^�t�@�C���̌ڋq�ԍ����擾
�L�@���p�ڋq�}�X�^�t�@�C���̖��L�[�Əƍ�
�N�@���p�ڋq�}�X�^�t�@�C���̗X�֔ԍ��C�Z���C�����y�ѓd�b�ԍ����擾
�P�@�ύX�����f�[�^�� U �t�@�C���ɏo��
|
|
�@�@�@�@ |
|
�@�@�@�@ |
|
�@�@�@�@ |
|
|
|
| �ݖ�Q |
�@�} 1 �̖��p�ڋq�}�X�^�t�@�C���̓��e�́C�����C�ڋq�f�[�^�x�[�X�̓��e�����̂܂ܕ��בւ������̂Ƃ��č쐬�����̂ŁC�ߋ� 1
�N�Ԃ̐\���ݎ��тȂǂ��̏����ɕK�v�łȂ����ڂ��܂�ł����B���p�ڋq�}�X�^�t�@�C���̓��e�Ƃ��ĕK�v�ȍ��ڂ̐������g�������C�Q�̒�����I�ׁB |
�@�ڋq�ԍ�
�@����
�@�Z��
�@�d�b�ԍ�
 �@���L�[ �@���L�[
 �@�X�֔ԍ� �@�X�֔ԍ�
| �ݖ�R |
�@�} 2 ����
�ɓ���鐳�����������C�Q�̒�����I�ׁB |
| �ݖ�S |
�@�} 2 �̏��� 8 �ōs���������C�Q�̒������I�ׁB |
|
��U�`��X�܂ł́A�I����ł��B�P��݂̂�I�����Ă��������B
|
|
�@���� C �v���O�����̐����y�уv���O������ǂ�ŁC�ݖ�ɓ�����B
�k�v���O�����̐����l
�ȒP�ȍ\���������������͂��āC�v�f�ɕ�������v���O�������쐬�����B
(1)�@�^�O�t��������̍\���K�����C���̂悤�ɒ�`����B�����ŁC�\���̋L�q�ɗp����L���̈Ӗ����C�\ 1 �̂悤�ɒ�߂�B�܂��C<�C> �y�� /
�́C����v�f�ł���B
�A�@�\�P�@�\���̋L�q�ɗp����L���̈Ӗ�
|
�L��
|
�Ӗ�
|
|
::=
|
��`���� |
|
|
|
���� |
|
{ }*
|
�g{�h�Ɓg}�h�ň͂܂ꂽ�\���v�f�� 0 ��ȏ�̌J�Ԃ� |
�^�O�t�������� ::= {�^�O�\��}*
�^�O�\�� ::= �J�n�^�O�@�^�O�̒l�@{�^�O�\��}*�@�I���^�O
�J�n�^�O ::= <�^�O��>
�I���^�O ::= </�^�O��>
�^�O�� ::= <�C>�C/ �y�сg\0�h���܂܂Ȃ�������
�^�O�̒l ::= <�C>�C/ �y�сg\0�h���܂܂Ȃ������� | ����
������ ::= {����}*
(2)�@�v���O�����̎d�l�́C���̂Ƃ���ł���B
�@�� parse_ml_string
�́C�^����ꂽ�^�O�t�������� mlstr ��v�f�ɕ������āC�J�n�^�O�̏o�����ɗv�f�z�� elmtbl �Ɋi�[����B�v�f���́C�ϐ�
elmnum�Ɋi�[����B�����ŁC�v�f�͎��̍\���̂ŕ\���B
typedef struct {
char *tag; /* �^�O�� */
int depth; /* ����q�̐[��(1,2,�c) */
char *value; /* �^�O�̒l */
} ELEMENT;
�@�^�O�t��������Ɋ܂܂��^�O�̗v�f�����C256
���邱�Ƃ͂Ȃ��B
�@�^������^�O�t��������ɁC�\���̌��͂Ȃ��B
(3)�@�^�O�\�����C�ʂ̃^�O�\�����܂ނ��Ƃ�����i�} 1 �Q�Ɓj�B

>�}�P�@����q�ɂȂ����^�O�\���̗�
(4)�@����q�̐[���́C�ŏ�ʂ̃^�O�\���� 1 �Ƃ��āC��ʂ��牺�ʂɌ������āC1�C2�C3�C�c �Ƃ���B
(5)�@�} 2 �̃^�O�t��������ɑ���v���O�����̎��s���ʂ́C�\ 2 �̂Ƃ���ł���B
<STUDENT>BILL<AGE>14</AGE><SCHOOL>Junior
<PLACE>Minato</PLACE></SCHOOL></STUDENT> |
�@�@�@�@���@������ɉ��s�͊܂܂Ȃ�
�@�@�@�@�@�@�@�@�@�@�}�Q�@�^�O�t�������� mlstr �̒l
�@�@�@�@�@�@�\�Q�@�v�f�z�� elmtbl
|
�^�O���@tag
|
����q�̐[���@depth
|
�^�O�̒l�@value
|
| �gSTUDENT�h�ւ̃|�C���^ |
1
|
�gBILL�h�ւ̃|�C���^ |
| �gAGE�h�ւ̃|�C���^ |
2
|
�g14�h�ւ̃|�C���^ |
| �gSCHOOL�h�ւ̃|�C���^ |
2
|
�gJunior�h�ւ̃|�C���^ |
| �gPLACE�h�ւ̃|�C���^ |
3
|
�gMinato�h�ւ̃|�C���^ |
�k�v���O�����l
#define MAXELMNUM 256
typedef struct {
�@�@ char *tag;
�@�@int depth;
�@�@char *value;
} ELEMENT;
char *parse_ml_data(char *, int);
ELEMENT elmtbl[MAXELMNUM];
int elmnum = 0;
void parse_ml_string(char *mlstr)
{
�@�@while (*mlstr != '\0') {
�@�@mlstr = parse_ml_data(mlstr + 1, 1);
�@�@}
}
char *parse_ml_data(char *mlstr, int level)
�o |
| �@�@/* �J�n�^�O���� */ |
| �@�@elmtbl[elmnum].tag =; |
�@�@elmtbl[elmnum].depth = level;
�@�@for (; *mlstr != '>'; mlstr++);
�@�@*mlstr = '\0';
�@�@/* �^�O�̒l���� */
�@�@elmtbl[elmnum].value = ;
�@�@for (mlstr++; *mlstr != '<'; mlstr++);
�@�@*mlstr = '\0';
�@�@ ;
�@�@/* ���ʂ̃^�O�\������ */
�@�@while ( )
�@�@�@mlstr = parse_ml_data(mlstr + 1, level + 1);
�@�@/* �I���^�O���� */
�@�@for (mlstr += 2; *mlstr != '>'; mlstr++);
�@�@return mlstr + 1;
�@�@}
|
�ݖ��@�v���O��������
�ɓ���鐳�����������C�Q�̒�����I�ׁB
a�Cb �Ɋւ���Q
�A�@mlstr�@�@�@�@�C�@++mlstr�@�@�@�@�E�@mlstr + 1
�G�@*mlstr�@�@�@�@�I�@*(++mlstr)�@�@�@�@�J�@*mlstr++
�L�@*(mlstr + 1)
c �Ɋւ���Q
�A�@elmnum++�@�@�@�@�C�@level++�@�@�@�@�E�@mlstr++
�G�@*elmnum++�@�@�@�@�I�@*level++�@�@�@�@�J�@*mlstr++
d �Ɋւ���Q
�A�@*(mlstr + 1) == '<'�@�@�@�@�C�@*(mlstr + 1) != '<'
�E�@*(mlstr + 1) == '/'�@�@�@�@�G�@*(mlstr + 1) != '/'
�I�@*(mlstr + 1) == '>'�@�@�@�@�J�@*(mlstr + 1) != '>'
|
|
|
�@�@�@�@ |
|
�@�@�@�@ |
|
�@�@�@�@ |
|
|
| �@�@ |
|
�@���� COBOL �v���O�����̐����y�уv���O������ǂ�ŁC�ݖ� 1�C2 �ɓ�����B
�k�v���O�����̐����l
A �Ђł́C�Ј��̕K�{���C�R�[�X�̏C���������o�ȗ� 80��
�ȏ�ƒ�߂Ă���B�N�x���ɔN�Ԏ�u�����t�@�C���ɓo�^����Ă���o�ȏ���C�C���������ǂ����肷��B
(1)�@�N�Ԏ�u�����t�@�C���i4 ���`���N 3 ���j�̃��R�[�h�l���́C���̂Ƃ���ł���B
|
��u�ԍ�
|
�C������
|
���Ɖ�
|
�o�ȏ�
|
|
���C�R�[�h
|
�Ј��ԍ�
|
�� 1 ��
|
�c
|
�� 15 ��
|
|
6 ����
|
6 ����
|
1 ����
|
2 ����
|
1 ����
|
�c
|
1 ����
|
�@��u�ԍ����L�[�Ƃ�������t�@�C���ł���B
�@���Ɖɂ͌��C�̎��Ƃ̎��{���L�^����Ă���C�e���C�̎��Ɖ� 1 �`
15 �ł���B
(2)�@�N�Ԏ�u�����t�@�C���ɑ��鏈���́C���̂Ƃ���ł���B
�@�N�x�n�߂ɁC�o�ȏi�� 1 �` 15 ��j�����ׂ� �O �ɂ���B
�@�Ј��̎��Ƃւ̏o�ȏi1�F�o�ȁC 0�F���ȁj���ƂɋL�^����B
�@�N�x���ɏo�ȏ��m�F���āC���Ɖ� 80��
�ȏ�̏o�Ȃ��������ꍇ�͏C��������gY�h�ɂ��C80�� �����̏ꍇ�́gN�h�ɂ���B
�k�v���O�����l
DATA DIVISION.
FILE SECTION.
FD ATTENDANCE-F.
01 ATTENDANCE-R.
�@�@03 A-ID.
�@�@�@�@05 A-COURSE PIC X(6).
�@�@�@�@05 A-EMPLOYEE PIC X(6).
�@�@03 A-COMPLETION PIC X.
�@�@03 A-SESSIONS PIC 9(2).
�@�@03 A-STATUS.
�@�@�@�@05 A-ATTENDANCE OCCURS 15 PIC X.
WORKING-STORAGE SECTION.
01 W-ATTENDANCE PIC 9(2).
01 END-SW PIC X VALUE SPACE..
01 W-COMPLETION PIC 9(3).
PROCEDURE DIVISION.
START-RTN.
�@�@�@OPEN I-O ATTENDANCE-F.
�@�@�@PERFORM UNTIL END-SW = "E"
�@�@�@�@�@READ ATTENDANCE-F
�@�@�@�@�@�@�@AT END MOVE "E" TO END-SW
�@�@�@�@�@�@�@NOT AT END PERFORM CHECK-RTN
�@�@�@�@�@END-READ END-PERFORM.
�@�@�@CLOSE ATTENDANCE-F.
�@�@�@STOP RUN.
|
CHECK-RTN.
�@�@ MOVE ZERO TO W-ATTENDANCE. |
| �@�@ INSPECT �@ |
TALLYING W-ATTENDANCE FOR ALL "1".
�@�@ COMPUTE W-COMPLETION = A-SESSIONS * 8.
�@�@IF �@
�@�@THEN
�@�@�@�@ �@�@MOVE "Y" TO A-COMPLETION
�@�@ELSE
�@�@�@�@�@�@ MOVE "N" TO A-COMPLETION
�@�@END-IF.
�@�@ REWRITE ATTENDANCE-R INVALID DISPLAY "REWRITE ERROR"�C A-ID. |
| �ݖ�P |
�@�v���O�������� �ɓ���鐳�����������C�Q�̒�����I�ׁB |
a �Ɋւ���Q
�A�@A-ATTENDANCE�@�@�@�@�C�@A-STATUS
�E�@ATTENDANCE-F�@�@�@�@�G�@ATTENDANCE-R
b �Ɋւ���Q
�A�@W-ATTENDANCE * 10 >= W-COMPLETION
�C�@W-ATTENDANCE >= W-COMPLETION * 0.8
�E�@W-COMPLETION >= W-ATTENDANCE
�G�@W-COMPLETION >= W-ATTENDANCE * 0.8
�Q
�A�@A-COURSE�@�@�@�@�C�@A-EMPLOYEE�@�@�@�@�E�@A-ID
�G�@���ďo���@�@�@�@�I�@���I�ďo���@�@�@�@�J�@���ďo��
|
|
|
| �@ |
|
�@���� Java �v���O�����̐����y�уv���O������ǂ�ŁC�ݖ�ɓ�����B
�k�v���O�����̐����l
�v���O�����́C����ߗ��i������ A �Ђ̍ɊǗ��V�X�e���Ŏg�p����N���X�Ƃ��̃e�X�g�p�N���X����Ȃ�B���� A
�ЂŎ�舵�����i�̓X���b�N�X�iSlacks�j�ƃW�[���Y�iJeans�j�ł���C�����ɋ��ʂȑ����ł���i�ԁicode�j,
�T�C�Y�isize�j�y�ѐF�icolor�j�͒��ۃN���X Pants
�Œ�`����B�T�C�Y�y�ѐF�ɂ��ẮC���ꂼ��̑����l�������̒l�Ɠ��������ǂ����肷�郁�\�b�h�Ƃ��� sizeIs �y�� colorIs ���`����B
�W�[���Y�iJeans�j�́C�ł��������{�^�����߂ł��邩�t�@�X�i�[���߂ł��邩�����������ibuttonFront�j�����B
�e�X�g�p�N���X�̃��\�b�h main �����s����ƁC���̎��s���ʂ�B
S1, 31, Black
S2, 31, Black
J1, 32, Black, zipper
J2, 34, Blue,
button
true
true
false
false |
�}�@���s����
�k�v���O�����l
public class TestPants { // �e�X�g�p�N���X
public static void main(String[] args) {
Pants[] pants = {
new Slacks("S1", 31, "Black"),
new Slacks("S2", 31, "Black"),
new Jeans("J1", 32, "Black", false),
new Jeans("J2", 34, "Blue", true),
};
String black = new String("Black");
for (int i = 0; i < pants.length; i++) {
System.out.println(pants[i]);
}
System.out.println(pants[0].sizeIs(31));
System.out.println(pants[1].colorIs(black));
System.out.println(pants[2].sizeIs(30));
System.out.println(pants[3].colorIs(black));
}
}
abstract class Pants {
�@�@String code;
�@�@int size;
�@�@String color;
�@�@Pants(String code,
�@�@int size, String color) {
�@�@�@�@this.code = code;
�@�@�@�@this.size = size;
�@�@�@�@this.color = color;
�@�@}
�@�@public boolean sizeIs(int size) { |
�@�@�@��eturn �@;
�@�@}
�@�@public boolean colorIs(String color) {
�@�@�@ return �@;
�@�@}
�@�@public String toString() {
�@�@�@ return code + ", " + size + ", " + color;
�@�@}
} |
class Slacks extends Pants {
�@�@Slacks(String code, int size, String color) {
�@�@�@super(code, size, color);
�@�@}
�@}
class Jeans extends Pants {
�@�@boolean buttonFront;
�@�@Jeans(String code, int size, String color, boolean buttonFront) {
�@�@;
this.buttonFront = buttonFront;
public String toString() {
�@�@return ;
�@�@}
} |
�ݖ��@�v���O��������
�ɓ���鐳�����������C�Q�̒�����I�ׁB
a�Cb �Ɋւ���Q
�A�@this.size = size�@�@�@�@�@�@�@�C�@this.size == size
�E�@this.size.equals(size)�@�@�@�@�G�@this.color = color
�I�@this.color == color�@�@�@�@�@�J�@this.color.equals(color)
c �Ɋւ���Q
�A�@super()
�C�@super(buttonFront)
�E�@super(code, size, color)
�G�@super(code, size, color, buttonFront)
d �Ɋւ���Q
�A�@code + ", " + size + ", " + color
�C�@code + ", " + size + ", " + color + ", " + buttonFront
�E�@super.toString() + ", " + buttonFront
�G�@super.toString() + ", " + (buttonFront ? "button" : "zipper")
|
|
|
�@�@�@�@ |
|
�@�@�@�@ |
|
�@�@�@�@ |
|
|
| �@ |
|
���̃A�Z���u���v���O�����̐����y�уv���O������ǂ�ŁC�ݖ� 1 �` 3 �ɓ�����B
�k�v���O�����̐����l
���v���O���� MULT �́C���̐��� m �� n �̐ρim�~n�j�����߂�B
(1)�@GR1 �� GR2 �ɁC���ꂼ�ꎟ�̒l���i�[����āC��v���O��������n�����B
GR1 : m
GR2 : n
(2)�@�v�Z���ʂ� GR0 �Ɋi�[���āC��v���O�����ɕԂ��B
(3)�@�v�Z���ʂ́C���ӂ�Ȃ����̂Ƃ���B
(4)�@GR0 �������āC���v���O�����Ŏg�p����ėp���W�X�^�̓��e�͕ۑ������B
�k�v���O�����l
�i�s�ԍ��j
| �@1�@MULT�@�@START�@�@�@�@�@�@�@�@ ; |
| �@2�@�@�@�@�@�@ PUSH�@ 0,GR1�@�@�@�@; ���W�X�^�̑ޔ� |
| �@3�@�@�@�@ �@�@PUSH�@ 0,GR2�@�@�@�@; |
�@4�@�@�@�@�@�@ �G; ���ʂ������� �G; ���ʂ������� |
| �@5�@LOOP�@�@SRL�@�@GR2,1�@�@�@�@; |
| �@6�@�@�@�@ �@�@JOV�@�@ON�@�@ �@�@�@ ; |
| �@7�@�@�@�@ �@�@JZE�@�@�eIN�@�@�@ �@ �@; |
| �@8�@�@�@�@�@�@ JUMP�@SHIFT�@�@�@�@; |
| �@9�@ON�@�@�@�G |
| 10�@SHIFT�@�@SLL�@�@GR1,1�@�@�@�@; |
| 11�@�@�@�@�@�@ JUMP�@ LOOP�@�@ �@; |
| 12�@FIN�@ �@�@POP�@�@GR2�@�@�@�@�@; ���W�X�^�̕��� |
| 13�@�@�@�@ �@�@POP�@�@GR1�@�@�@�@�@; |
| 14�@�@�@�@�@�@ RET�@�@�@�@�@�@�@ �@�@ ; |
| 15�@�@�@�@�@�@ END�@�@�@�@�@�@�@�@ �@ ; |
| �ݖ�P |
�@�v���O��������
�ɓ���鐳�����������C�Q�̒�����I�ׁB |
�Q
�A�@ADDA GR0,GR1�@�@�@�@�C�@ADDA GR0,GR2
�E�@ADDA GR1,GR2�@�@�@�@�G�@ADDA GR2,GR1
�I�@SUBA GR0,GR0�@�@�@�@�J�@SUBA GR0,GR1
�L�@SUBA GR0,GR2�@�@�@�@�N�@SUBA GR1,GR2
|
| �@ |
| �ݖ�Q |
�@GR1 �� 3�CGR2 �� 38 ���i�[���āC��v���O��������Ăяo�����Ƃ��C�s�ԍ� 11 �� JUMP
���߂����s�����Ƃ��Đ������������C�Q�̒�����I�ׁB |
|
| �@ |
| �ݖ�R |
�@�ݖ� 2 �ɂ����āC�s�ԍ� 11 �� JUMP ���߂� 2 ��ڂɎ��s�����Ƃ��� GR0 �̓��e�Ƃ��Đ������������C�Q�̒�����I�ׁB |
|
|
| �@ |
��P�O�`��P�R�܂ł́A�I����ł��B�P��݂̂�I�����Ă��������B
|
|
�@���� C �v���O�����̐����y�уv���O������ǂ�ŁC�ݖ� 1 �` 4 �ɓ�����B
�k�v���O�����̐����l
���H�������v���O�����ł���B
(1)�@�} 1 �Ɏ������悤�ȏc 8 �s�� 8 ��̖ڏ�ɕ\�����ꂽ���H�}�̃f�[�^�� 2 �����z�� M
�Ɋi�[����Ă���B�D�F�ɓh��Ԃ���Ă��鏡�����H�̕ǂ������Ă���C���F�̏������������Ă���B
(2)�@�����̏��ɂ͎n�_�������R�[�h�i0xf0�j���C�o���̏��ɂ͏I�_�������R�[�h�i0xf1�j���C���̏��ɂ͓��������R�[�h�i0x00�j���C�ǂ̏��ɂ͕ǂ������R�[�h�i0xff
�j��
�i�[�������B
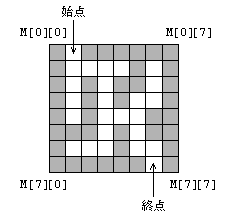
�}�P�@���H�̗�
(3)�@���H�̊O���ƂȂ鏡�iM �̉����W���͏c���W�� 0 ���� 7 �ł��鏡�j�́C�n�_�ƏI�_�������Ă��ׂĕǂł���B
(4)�@���̃v���O�����Ŏg�p���Ă�����ϐ��̗p�r�́C���̂Ƃ���ł���B
|
�ϐ���
|
�p�r
|
|
M
|
���H�}�f�[�^�̊i�[��i2 �����z��j |
|
x
|
���H�T�����̏��̉����W |
|
y
|
���H�T�����̏��̏c���W |
|
dir
|
���H�T�����̐i�s���� |
�����̑��ϐ��ɏ����l��ݒ肵�C�� maze ���Ăяo�����Ƃɂ���Ė��H��T�����C��������o���܂ł̓������߂�B
�k�v���O�����l
�i�s�ԍ��j
1 #define UP 0
2 #define RIGHT 1
3 #define DOWN 2
4 #define LEFT 3
5 #define ROAD 0x00 /* ���̃R�[�h */
6 #define WALL 0xff /* �ǂ̃R�[�h */
7 #define SMAX 8
8 #define ENTRANCE 0xf0 /* �n�_�̃R�[�h */
9 #define EXIT 0xf1 /* �I�_�̃R�[�h */
10
11 int rcheck(void);
12 int fcheck(void);
13 void go(void);
14 void maze(void);
15
16 int M[SMAX][SMAX], x, y, dir;
17
18 void maze()
19 {
20 while ( M[y][x] != EXIT ) {
21 if ( ( rcheck() == ROAD ) ||
22 ( rcheck() == EXIT ) ) {
23 dir = ( dir+1 ) % 4;
24 go();
25 }
26 else if ( ( fcheck() == ROAD ) ||
27 ( fcheck() == EXIT ) ) go();
28 else dir = ( dir+3 ) % 4;
29 }
30 return;
31 }
32
33 int rcheck()
34 {
35 if ( dir == UP ) return M[y][x+1];
36 else if ( dir == RIGHT ) return M[y+1][x];
37 else if ( dir == DOWN ) return M[y][x-1];
38 else return M[y-1][x];
39 }
40
41 int fcheck()
42 {
43 if ( dir == UP ) return M[y-1][x];
44 else if ( dir == RIGHT ) return M[y][x+1];
45 else if ( dir == DOWN ) return M[y+1][x];
46 else return M[y][x-1];
47 }
48
49 void go()
50 {
51 if ( dir == UP ) y--;
52 else if ( dir == RIGHT ) x++;
53 else if ( dir == DOWN ) y++;
54 else x--;
55 }
| �ݖ�P |
�@�} 2 �Ɏ������H���C���̃v���O�����ɂ���ĉ��������Ƃ��Đ������������C�Q�̒�����I�ׁB�}���� �` 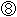 �́C���̈ʒu�������Ă���B�����ŁC�� maze ���Ăяo���Ƃ��̑��ϐ� x�Cy�Cdir �̒l�͎��̂Ƃ���Ƃ���B
�́C���̈ʒu�������Ă���B�����ŁC�� maze ���Ăяo���Ƃ��̑��ϐ� x�Cy�Cdir �̒l�͎��̂Ƃ���Ƃ���B
|
x = 1
y = 0
dir = DOWN
�}�Q�@���H�̏��̈ʒu
|
|
| �ݖ�Q |
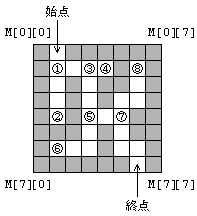
�@�} 3 �Ɏ������H�̏ꍇ�C�T���̓��Ɋւ���L�q�Ƃ��Đ������������C�Q�̒�����I�ׁB�����ŁC�� maze ���Ăяo���Ƃ��̑��ϐ�
x�Cy�Cdir �̒l�͎��̂Ƃ���Ƃ���B |
�@�@�@�@x = 1
�@�@�@�@y = 0
�@�@�@�@dir = DOWN
�}�R�@�������H
|
| �@ |
| �ݖ�R |
�@�n�_�y�яI�_���܂߂āC�ʉ߂������̈ʒu�Ɛi�s�������L�^���邽�߂ɁC�v���O�������Ɏ��̕���lj����邱�Ƃɂ����B����lj�����K�Ȉʒu���Q�̒�����I�ׁB
�@�Ȃ��C�v���O�����̐擪�� #include <stdio.h> ��������̂Ƃ���B |
printf("dir=%d y=%d x=%d\n", dir, y, x);
|
|
| �ݖ�S |
�@���H�̉�@�Ƃ��āC�� rcheck �̑���ɁC���̊� lcheck ���g�p���邱�Ƃɂ����B�s�ԍ� 11�C21 �y�� 22 �ł̊� rcheck
�� lcheck �ɒu��������B
�@���̏ꍇ�C�v���O�������ōX�ɕύX���ׂ��ӏ��Ƃ��Đ������������C�Q�̒�����I�ׁB
|
int lcheck()
{
if ( dir == UP ) return M[y][x-1];
else if ( dir == RIGHT ) return M[y-1][x];
else if ( dir == DOWN ) return M[y][x+1];
else return M[y+1][x];
}
|
|
|
|
�@���� COBOL �v���O�����̐����y�уv���O������ǂ�ŁC�ݖ� 1�C2 �ɓ�����B
�k�v���O�����̐����l
���i�̖��́C���i�Ȃǂ�o�^�������i�}�X�^�t�@�C���i M �t�@�C���ƌĂԁj������B M �t�@�C���̍X�V��o�^���Ă���g�����U�N�V�����t�@�C���i T
�t�@�C���ƌĂԁj��p���� M �t�@�C���̒lj��C�ύX�y�э폜���s���v���O�����ł���B
(1)�@M �t�@�C���y�� T �t�@�C���̃��R�[�h�l���́C���̂Ƃ���ł���B
|
���i�R�[�h
13 ����
|
���ރR�[�h
6 ����
|
���i
6 ����
|
����
40 ����
|
(2)�@M �t�@�C���́C���i�R�[�h���L�[�Ƃ�������t�@�C���ł���B
(3)�@M �t�@�C���ւ̍X�V�����́CT �t�@�C���̏��i�R�[�h�C���ރR�[�h�C���i�y�і��̂̓��e�ɂ���āC���̏������s���ƂƂ��ɁC���ʂ�����B�������CT
�t�@�C���̏��i�R�[�h�́C�ł͂Ȃ��B
�@M �t�@�C���ւ̒lj�
T �t�@�C���̏��i�R�[�h�� M �t�@�C���ɖ��o�^�ŁCT �t�@�C���̏��i�R�[�h�C���ރR�[�h�C���i�y�і��̂����ׂċL�q����Ă���Ƃ��́C���̃��R�[�h�� M
�t�@�C���ɒlj�����B
�@M �t�@�C���̕ύX
T �t�@�C���̏��i�R�[�h�� M �t�@�C���ɓo�^�ς݂ŁCT �t�@�C���̕��ރR�[�h�C���i�y�і��̂̏��Ȃ��Ƃ�����L�q����Ă���Ƃ��C���̍��ڂ̓��e�� M
�t�@�C���̑Ή����鍀�ڂ�u��������B
�@M �t�@�C������̍폜
T �t�@�C���̏��i�R�[�h�� �l �t�@�C���ɓo�^�ς݂ŁCT �t�@�C���̕��ރR�[�h�C���i�y�і��̂����ׂċ̂Ƃ��́CM
�t�@�C�����炻�̏��i�R�[�h�̃��R�[�h���폜����B
�@T �t�@�C���̃G���[
T �t�@�C���̏��i�R�[�h�� M �t�@�C���ɖ��o�^�ŁCT �t�@�C���̕��ރR�[�h�C���i�y�і��̂Ɉ�ł��̍��ڂ�����ꍇ�́CT
�t�@�C���̃��R�[�h�G���[�Ƃ��Ĉ���B
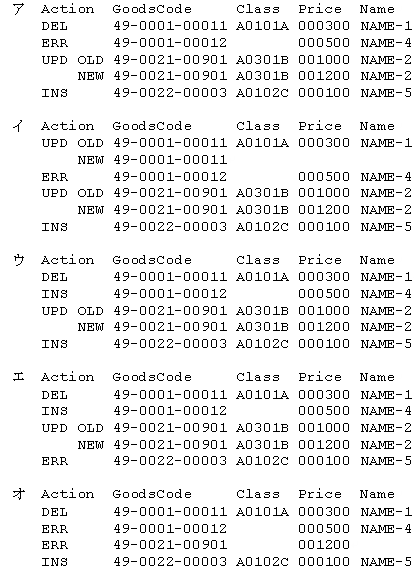
(4)�@�������ʂ̈�́C���̂Ƃ���ł���B
Action
|
GoodsCode
|
Class
|
Price
|
Name
|
INS
|
XXXXXXXXXXXXX
|
XXXXXX
|
XXXXXX
|
XXXXXXXXXXX
|
�c
|
XXXXXXXXXXXXX
|
UPD OLD
|
XXXXXXXXXXXXX
|
XXXXXX
|
XXXXXX
|
XXXXXXXXXXX
|
�c
|
XXXXXXXXXXXXX
|
�@�@NEW
|
XXXXXXXXXXXXX
|
XXXXXX
|
XXXXXX
|
XXXXXXXXXXX
|
�c
|
XXXXXXXXXXXXX
|
DEL
|
XXXXXXXXXXXXX
|
XXXXXX
|
XXXXXX
|
XXXXXXXXXXX
|
�c
|
XXXXXXXXXXXXX
|
ERR
|
XXXXXXXXXXXXX
|
XXXXXX
|
XXXXXX
|
XXXXXXXXXXX
|
�c
|
XXXXXXXXXXXXX
|
|
�@�ᒆ�̍��� Action �̈Ӗ��́C���̂Ƃ���ł���B INS �FM
�t�@�C���ւ̒lj� UPD�FM �t�@�C���̕ύX�ł���COLD ���ύX�O�CNEW ���ύX��̓��e DEL�FM �t�@�C������̍폜 ERR�FT
�t�@�C���̃��R�[�h�G���[
�@����ȊO�̍��ڂɂ́CAction �� ERR �ł���Ƃ��� T
�t�@�C���̓��e���CERR �ȊO�̂Ƃ��� M �t�@�C���̓��e������B
�@���o���̈́C�ŏ��� 1 �x�����s���B
�k�v���O�����l
| DATA DIVISION. |
| FILE SECTION. |
| FD�@MASTER-FILE. |
| 01�@MASTER-REC. |
| �@�@02�@GOODS-MAS�@�@�@�@�@PIC�@X(13). |
| �@�@02�@DATA-MAS. |
| �@�@�@�@03�@CLASS-MAS�@�@�@PIC�@X(06). |
| �@�@�@�@03�@PRICE-MAS�@�@�@PIC�@X(06). |
| �@�@�@�@03�@NAME-MAS�@�@�@ PIC�@X(40). |
| FD�@TRANS-FILE. |
| 01�@TRANS-REC. |
| �@�@02�@GOODS-TRA�@�@�@�@�@PIC�@X(13). |
| �@�@02�@DATA-TRA. |
| �@�@�@�@03�@CLASS-TRA�@�@�@PIC�@X(06). |
| �@�@�@�@03�@PRICE-TRA�@�@�@PIC�@X(06). |
| �@�@�@�@03�@NAME-TRA�@�@�@ PIC�@X(40). |
| FD�@PRINT-FILE. |
| 01�@PRINT-REC�@�@�@�@�@�@�@PIC�@X(77). |
| WORKING-STORAGE SECTION. |
| 01�@TRANS-EOF�@�@�@�@�@�@�@PIC�@9(01) VALUE 0. |
| 01�@PRINT1�@�@�@�@�@�@�@�@ PIC�@X(41) VALUE |
| �@ "Action�@ GoodsCode�@�@ Class�@Price�@Name". |
| 01�@PRINT2 VALUE SPACE. |
| �@�@03�@ACTION-PRI�@�@�@�@ PIC�@X(07). |
| �@�@03�@�@�@�@�@�@�@�@�@�@�@PIC�@X(02). |
| �@�@03�@GOODS-PRI�@�@�@�@�@PIC�@X(13). |
| �@�@03�@�@�@�@�@�@�@�@�@�@ PIC�@X. |
| �@�@03�@CLASS-PRI�@�@�@�@�@PIC�@X(06). |
| �@�@03�@�@�@�@�@�@�@�@�@�@ PIC�@X. |
| �@�@03�@PRICE-PRI�@�@�@�@�@PIC�@X(06). |
| �@�@03�@�@�@�@�@�@�@�@�@�@ PIC�@X. |
| �@�@03�@NAME-PRI�@�@�@�@�@ PIC�@X(40). |
| PROCEDURE DIVISION. |
| TRANS-READ-RTN. |
| �@�@OPEN I-O MASTER-FILE INPUT TRANS-FILE OUTPUT PRINT-FILE. |
| �@�@WRITE PRINT-REC FROM PRINT1 AFTER PAGE. |
| �@�@PERFORM UNTIL TRANS-EOF = 1 |
| �@�@�@ READ TRANS-FILE |
| �@�@�@�@�@AT END |
| �@�@�@�@�@�@ MOVE 1 TO TRANS-EOF |
| �@�@�@�@�@NOT AT END |
| �@�@�@�@�@�@ PERFORM UPDATE-RTN |
| �@�@�@ END-READ |
| �@�@END-PERFORM. |
| �@�@CLOSE MASTER-FILE TRANS-FILE PRINT-FILE. |
| �@�@STOP RUN. |
| UPDATE-RTN. |
| �@�@MOVE�@ TO
|
| �@�@READ MASTER-FILE |
| �@�@�@ INVALID KEY |
�@�@�@�@�@IF �@ |
| �@�@�@�@�@THEN |
| �@�@�@�@�@�@ PERFORM MOVE-TRA-RTN |
| �@�@�@�@�@�@ MOVE "INS" TO ACTION-PRI |
| �@�@�@�@�@�@ WRITE PRINT-REC FROM PRINT2 AFTER 1 |
| �@�@�@�@�@�@ WRITE MASTER-REC FROM TRANS-REC |
| �@�@�@�@�@ELSE |
| �@�@�@�@�@�@ PERFORM MOVE-TRA-RTN |
| �@�@�@�@�@�@ MOVE "ERR" TO ACTION-PRI |
| �@�@�@�@�@�@ WRITE PRINT-REC FROM PRINT2 AFTER 1 |
| �@�@�@�@�@END-IF |
| �@�@�@ NOT INVALID KEY |
| �@�@�@�@�@IF�@= SPACE THEN |
| �@�@�@�@�@�@ PERFORM MOVE-MAS-RTN |
| �@�@�@�@�@�@ DELETE MASTER-FILE |
| �@�@�@�@�@�@�@�@INVALID KEY |
| �@�@�@�@�@�@�@�@�@ DISPLAY "DELETE ERROR" |
| �@�@�@�@�@�@�@�@NOT INVALID KEY |
| �@�@�@�@�@�@�@�@�@ MOVE "DEL" TO ACTION-PRI |
| �@�@�@�@�@�@�@�@�@ WRITE PRINT-REC FROM PRINT2 AFTER 1 |
| �@�@�@�@�@�@ END-DELETE |
�@�@�@�@�@ELSE�@�@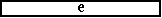 |
| �@�@�@�@�@�@ MOVE "UPD OLD�h TO ACTION-PRI |
| �@�@�@�@�@�@ IF CLASS-TRA NOT = SPACE THEN |
| �@�@�@�@�@�@�@�@MOVE CLASS-TRA TO CLASS-MAS |
| �@�@�@�@�@�@ END-IF |
| �@�@�@�@�@�@ IF PRICE-TRA NOT = SPACE THEN |
| �@�@�@�@�@�@�@�@MOVE PRICE-TRA TO PRICE-MAS |
| �@�@�@�@�@�@ END-IF |
| �@�@�@�@�@�@ IF NAME-TRA NOT = SPACE THEN |
| �@�@�@�@�@�@�@�@MOVE NAME-TRA TO NAME-MAS |
| �@�@�@�@�@�@ END-IF |
| �@�@�@�@�@�@ WRITE PRINT-REC FROM PRINT2 AFTER 1 |
| �@�@�@�@�@�@ PERFORM MOVE-MAS-RTN |
| �@�@�@�@�@�@ REWRITE MASTER-REC |
| �@�@�@�@�@�@�@�@INVALID KEY |
| �@�@�@�@�@�@�@�@�@ DISPLAY "REWRITE ERROR" |
| �@�@�@�@�@�@�@�@NOT INVALID KEY |
| �@�@�@�@�@�@�@�@�@�@MOVE "NEW" TO ACTION-PRI |
| �@�@�@�@�@�@�@�@�@ WRITE PRINT-REC FROM PRINT2 AFTER 1 |
| �@�@�@�@�@�@ END-REWRITE |
| �@�@�@�@�@END-IF |
| �@�@END-READ. |
| MOVE-TRA-RTN. |
| �@�@MOVE GOODS-TRA TO GOODS-PRI. |
| �@�@MOVE CLASS-TRA TO CLASS-PRI. |
| �@�@MOVE PRICE-TRA TO PRICE-PRI. |
| �@�@MOVE NAME-TRA�@TO NAME-PRI. |
| MOVE-MAS-RTN. |
| �@�@MOVE GOODS-MAS TO GOODS-PRI. |
| �@�@MOVE CLASS-MAS TO CLASS-PRI. |
| �@�@MOVE PRICE-MAS TO PRICE-PRI. |
| �@�@MOVE NAME-MAS�@TO NAME-PRI. |
| �ݖ�P |
�@�v���O�������� �ɓ���鐳�����������C�Q�̒�����I�ׁB
|
a�Cb�Cd �Ɋւ���Q
�A�@CLASS-MAS�@�@�@�@�C�@CLASS-TRA�@�@�@�@�E�@DATA-MAS
�G�@DATA-TRA�@�@�@�@�I�@GOODS-MAS�@�@�@�@�J�@GOODS-TRA
�L�@NAME-MAS�@�@�@�@�N�@NAME-TRA�@�@�@�@�P�@PRICE-MAS
�R�@PRICE-TRA
c �Ɋւ���Q
�A�@CLASS-MAS = SPACE AND �@�@�@PRICE-MAS = SPACE AND NAME-MAS = SPACE
�C�@CLASS-MAS NOT = SPACE AND �@�@�@PRICE-MAS NOT = SPACE AND NAME-MAS
NOT = SPACE
�E�@CLASS-TRA = SPACE AND �@�@�@PRICE-TRA = SPACE AND NAME-TRA = SPACE
�G�@CLASS-TRA NOT = SPACE AND �@�@�@PRICE-TRA NOT = SPACE AND NAME-TRA
NOT = SPACE
�I�@DATA-MAS = SPACE
�J�@DATA-MAS NOT = SPACE
�L�@DATA-TRA = SPACE
�N�@DATA-TRA NOT = SPACE
e �Ɋւ���Q
�A�@MOVE MASTER-REC TO PRINT-REC
�C�@MOVE MASTER-REC TO TRANS-REC
�E�@MOVE TRANS-REC TO MASTER-REC
�G�@MOVE TRANS-REC TO PRINT-REC
�I�@PERFORM MOVE-MAS-RTN
�J�@PERFORM MOVE-TRA-RTN
|
|
�@�@�@�@ |
|
�@�@�@�@ |
|
�@�@�@�@ |
|
�@�@�@ |
|
|
| �@ |
| �ݖ�Q |
�@M �t�@�C���y�� T �t�@�C���Ɏ��̃��R�[�h������Ƃ��C���������ʂ��C�Q�̒�����I�ׁB |
M �t�@�C�� �@49-0001-00011A0101A000300NAME-1 �@49-0021-00901A0301B001000NAME-2
�@49-0031-00002B0102C000050NAME-3
T �t�@�C�� �@49-0001-00011 �@49-0001-00012 000500NAME-4 �@49-0021-00901
001200 �@49-0022-00003A0102C000100NAME-5
| �Q |
|
|
 |
�@�@
|
|
|
|
�@���� Java �v���O�����̐����y�уv���O������ǂ�ŁC�ݖ� 1 �` 3 �ɓ�����B
�k�v���O�����̐����l
�����Ђ̏��Ǘ�����œ�������R���s���[�^�̌��Ƃ��ă��[�N�X�e�[�V�����ƃp�[�\�i���R���s���[�^����Ă���Ă���B�����̃R���s���[�^�̒l������̉��i�̌v�Z���s���C�R���s���[�^�̎d�l�����i�̍~���ɐ��ďo�͂���v���O�����ł���B�R���s���[�^�̎d�l�́C���̎l����Ȃ�B
�@�햼�C������g���C�������e�ʁC���i
���̃v���O�����́C���̎l�̃N���X�ƈ�̃C���^�t�F�[�X�ō\�������B
Computer
�R���s���[�^�Ɋւ���N���X�ł���C���i��Ԃ����\�b�h getPrice�C���i���i�[���郁�\�b�h setPrice�C�d�l����ŕԂ����\�b�h
toString�C�l��������Ԃ����\�b�h getDiscountRate�C�y�ѐ���ۂɗp����f�[�^�̑召���r���郁�\�b�h compareWith
���`������B
Workstation
�N���X Computer �̃T�u�N���X�Ƃ��Ē�`���ꂽ���[�N�X�e�[�V�����Ɋւ���N���X�ł���C���[�N�X�e�[�V�����̒l��������Ԃ����\�b�h
getDiscountRate ���Ē�`���Ă���B
PersonalComputer
�N���X Computer �̃T�u�N���X�Ƃ��Ē�`���ꂽ�p�[�\�i���R���s���[�^�Ɋւ���N���X�ł���C�p�[�\�i���R���s���[�^�̒l��������Ԃ����\�b�h
getDiscountRate ���Ē�`���Ă���B
PriceUtility
�l������̉��i�̌v�Z�Ɛ�������邽�߂̃N���X�ł���C���i�̌v�Z���s�����\�b�h computeDiscountPrice�C�y�ѐ�����s�����\�b�h sort
���`������B
IComp
�召��r�̑Ώۂ�\���C���^�t�F�[�X�ł���C��r���s�����\�b�h compareWith ��錾���Ă���B
�v���O���� 1 �̃��\�b�h main �ƃv���O���� 2 �` 6 �̎��s���ʂ�}�Ɏ����B���̂Ƃ��C���\�b�h main �̏����́C���̂Ƃ���ł���B
(1)�@�l�̃R���s���[�^�̎d�l�����C�z�� computers �Ɋi�[����B
(2)�@�e�R���s���[�^�̎d�l���o�͂���B
(3)�@�l������̉��i�̌v�Z���s���B
(4)�@������s���B
(5)�@���ʂ��o�͂���B
Ws1, frequency:800, memory:256, price:300000
Pc1, frequency:450,
memory:128, price:180000
Ws2, frequency:800, memory:512, price:500000
Pc2, frequency:450, memory:256, price:200000
<sorted by price>
Ws2, frequency:800, memory:512, price:450000
Ws1, frequency:800, memory:256, price:270000
Pc2, frequency:450,
memory:256, price:160000
Pc1, frequency:450, memory:128,
price:144000
|
�}�@���s����
�k�v���O���� 1 �l
�i�s�ԍ��j
1 public class PriceSort {
2 public static void main(String[] args) {
3 Computer[] computers = {
4 new Workstation("Ws1", 800, 256, 300000),
5 new PersonalComputer("Pc1", 450, 128, 180000),
6 new Workstation("Ws2", 800, 512, 500000),
7 new PersonalComputer("Pc2", 450, 256, 200000),
8 };
9 for (int i = 0; i < computers.length; i++) {
10 System.out.println(computers[i]);
11 }
12 System.out.println("\n<sorted by price>");
13 PriceUtility.computeDiscountPrice(computers);
14 PriceUtility.sort(computers);
15 for (int i = 0; i < computers.length; i++) {
16 System.out.println(computers[i]);
17 }
18 }
19 }
�k�v���O���� 2 �l �i�s�ԍ��j
1 public interface IComp {
2 int compareWith(IComp a);
3 }
�k�v���O���� 3 �l �i�s�ԍ��j
| 1�@ public class Computer implements�@{ |
| 2�@�@�@String name; |
| 3�@�@�@int frequency; |
| 4�@�@�@int memory; |
| 5�@�@�@int price; |
| 6�@�@�@public Computer(String name, int frequency, |
| 7�@�@�@�@�@�@�@�@�@�@�@int memory, int price) { |
| 8�@�@�@�@ this.name = name; |
| 9�@�@�@�@ this.frequency = frequency; |
| 10�@�@�@�@ this.memory = memory; |
| 11�@�@�@�@ this.price = price; |
| 12�@�@�@} |
| 13�@�@�@public int getPrice() { |
| 14�@�@�@�@ return price; |
| 15�@�@�@} |
| 16�@�@�@public void setPrice(int price) { |
| 17�@�@�@�@ this.price = price; |
| 18�@�@�@}�@�@ |
| 19�@�@�@public String toString() { |
| 20�@�@�@�@ return name + ", frequency:" + frequency |
| 21�@�@�@�@�@�@�@+ ", memory:" + memory + ", price:" + price; |
| 22�@�@�@} |
| 23�@�@�@public double getDiscountRate() { |
| 24�@�@�@�@ return 0.0; |
| 25�@�@�@} |
| 26�@�@�@public int compareWith(IComp a) { |
| 27�@�@�@�@ Computer computer = ()a; |
| 28�@�@�@�@ return computer.price - this.price; |
| 29�@�@�@} |
| 30�@ } |
�k�v���O���� 4 �l �i�s�ԍ��j
1 public class Workstation extends Computer {
2 public Workstation(String name, int frequency,
3 int memory, int price) {
4 super(name, frequency, memory, price);
5 }
6 public double getDiscountRate() {
7 return 0.1;
8 }
9 }
�k�v���O���� 5 �l �i�s�ԍ��j
1 public class PersonalComputer extends Computer {
2 public PersonalComputer(String name, int frequency,
3 int memory, int price) {
4 super(name, frequency, memory, price);
5 }
6 public double getDiscountRate() {
7 return 0.2;
8 }
9 }
�k�v���O���� 6 �l �i�s�ԍ��j
| 1�@ public class PriceUtility { |
| 2�@�@�@public static void computeDiscountPrice(Computer[] a) { |
| 3�@�@�@�@ int newPrice; |
| 4�@�@�@�@ for (int i = 0; i < a.length; i++) { |
| 5�@�@�@�@�@�@newPrice = (int)(a[i].() |
| 6�@�@�@�@�@�@�@�@�@�@�@�@�@�@�@* (1 - a[i].getDiscountRate())); |
| 7�@�@�@�@�@�@a[i].setPrice(newPrice); |
| 8�@�@�@�@ } |
| 9�@�@�@} |
| 10�@�@�@public static void sort(IComp[] a) { |
| 11�@�@�@�@ // �P���}���@�ɂ�鐮�� |
| 12�@�@�@�@ int j; |
| 13�@�@�@�@ for (int i = 1; i < a.length; i++) { |
| 14�@�@�@�@�@�@IComp temp = a[i]; |
| 15�@�@�@�@�@�@for (j = i - 1; |
| 16�@�@�@�@�@�@�@�@ j >= 0 && temp.(a[j]) < 0; |
| 17�@�@�@�@�@�@�@�@ j--) { |
| 18�@�@�@�@�@�@�@ a[j + 1] = a[j]; |
| 19�@�@�@�@�@�@} |
| 20�@�@�@�@�@�@a[j + 1] = temp; |
| 21�@�@�@�@ } |
| 22�@�@�@} |
| 23�@ } |
�@
| �ݖ�P |
�@�v���O���� 3�C6 ���� �ɓ���鐳�����������C�Q�̒�����I�ׁB
|
�Q
| �A�@ |
compareWith�@�@�@�@ |
�C�@ |
computeDiscountPrice |
| �E�@ |
Computer�@�@�@�@ |
�G�@ |
getDiscountRate |
| �I�@ |
getPrice�@�@�@�@ |
�J�@ |
IComp |
| �L�@ |
PriceUtility�@�@�@ |
�N�@ |
sort |
|
|
�@�@�@�@ |
|
�@�@�@�@ |
|
�@�@�@�@ |
|
|
| �@ |
| �ݖ�Q |
�@�v���O���� 3 �̍s�ԍ� 28 ��
return computer.frequency - this.frequency;
�ɕύX�����Ƃ��̃v���O���� 1 �̍s�ԍ� 16 �̏o�͂Ƃ��Đ������������C�Q�̒�����I�ׁB
|
�Q
|
�A�@ |
Pc1, frequency:450, memory:128, price:144000 |
|
�@�@ |
Pc2, frequency:450, memory:256, price:160000 |
|
�@�@ |
Ws1, frequency:800, memory:256, price:270000 |
|
�@�@ |
Ws2, frequency:800, memory:512, price:450000 |
| �@ |
|
�C�@ |
Pc2, frequency:450, memory:256, price:160000 |
|
�@�@ |
Pc1, frequency:450, memory:128, price:144000 |
|
�@�@ |
Ws2, frequency:800, memory:512, price:450000 |
|
�@�@ |
Ws1, frequency:800, memory:256, price:270000 |
| �@ |
|
�E�@ |
Ws1, frequency:800, memory:256, price:270000 |
|
�@�@ |
Ws2, frequency:800, memory:512, price:450000 |
|
�@�@ |
Pc1, frequency:450, memory:128, price:144000 |
|
�@�@ |
Pc2, frequency:450, memory:256, price:160000 |
| �@ |
|
�G�@ |
Ws2, frequency:800, memory:512, price:450000 |
|
�@�@ |
Ws1, frequency:800, memory:256, price:270000 |
|
�@�@ |
Pc2, frequency:450, memory:256, price:160000 |
|
�@�@ |
Pc1, frequency:450, memory:128,
price:144000 |
|
| �@ |
| �ݖ�R |
�@�v���O���� 5 �̍s�ԍ� 7 ��
return 0.4;
�ɕύX�����Ƃ��C�e�R���s���[�^�̒l������̉��i�Ƃ��Đ������������C�Q�̒�����I�ׁB
|
|
| �Q |
| �@ |
Ws1
|
Pc1
|
Ws2
|
Pc2
|
|
�A
|
180000
|
108000
|
300000
|
120000
|
|
�C
|
180000
|
144000
|
300000
|
160000
|
|
�E
|
270000
|
108000
|
450000
|
120000
|
|
�G
|
270000
|
144000
|
450000
|
160000
|
|
|
|
|
|
|
|
|
|
�@���̃A�Z���u���v���O�����̐����y�уv���O������ǂ�ŁC�ݖ� 1 �` 3 �ɓ�����B
�k�v���O�����̐����l
�w�肳�ꂽ�͈͂̃������̓��e���C16 �i���Ƃ��ďo�͂��镛�v���O�����ł���B
(1)�@��v���O�����͔͈͂̐擪�A�h���X�� GR1 �ɁC�͈͂̏I�[�A�h���X�� GR2 �ɐݒ肵�C���v���O���� HEXDUMP ���ĂԁB
(2)�@���v���O���� HEXDUMP �ɂ���ďo�͂���郌�R�[�h�́C���̌`���ł���B
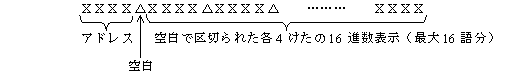
(3)�@���v���O���� HEXDUMP �́C�ʂ̕��v���O���� HEXCNV ���g�p����B HEXCNV �́CGR5 �Ɋi�[���ꂽ 1 ��̓��e�� 4 ������
16 �i������ɕϊ����C GR4 ���w���o�͗̈�Ɋi�[����B
�k�v���O�����l
| �@�@HEXDUMP START |
| �@�@�@�@�@�@RPUSH |
�@
|
| �@�@LP1�@�@ LAD�@�@GR4,OUTBUF�@�@ ; �o�̓|�C���^�̏����� |
| �@�@�@�@�@�@LAD�@�@GR3,16�@�@�@�@ ; �s���ꐔ�J�E���^�̏����� |
| �@�@�@�@�@�@LD�@�@ GR5,GR1 |
| �@�@�@�@�@�@CALL�@ HEXCNV�@�@�@�@ ; �A�h���X�� 16 �i�ϊ� |
| �@�@LP2�@�@ LD�@�@ GR5,=' ' |
| �@�@�@�@�@�@ST�@�@ GR5,0,GR4 |
| �@�@�@�@�@�@LAD�@�@GR4,1,GR4 |
| �@�@�@�@�@�@LD�@�@ GR5,0,GR1 |
| �@�@�@�@�@�@CALL�@ HEXCNV�@�@�@�@ ; 1 �ꕪ�� 16 �i�ϊ� |
| �@�@�@�@�@�@LAD�@�@GR1,1,GR1 |
| �@�@�@�@�@�@CPL�@�@GR1,GR2 |
| �@�@�@�@�@�@ |
| �@�@�@�@�@�@SUBA�@ GR3,=1 |
| �@�@�@�@�@�@JNZ�@�@LP2�@�@�@�@�@�@; 1 �s���i16 ��j�I���H |
| �@�@�@�@�@�@OUT�@�@OUTBUF,OUTLEN |
| �@�@�@�@�@�@JUMP�@ LP1 |
| �@�@FIN�@�@ LAD�@�@GR5,OUTBUF |
| �@�@�@�@�@�@ |
| �@�@�@�@�@�@ST�@�@ GR4,LENG |
| �@�@�@�@�@�@OUT�@�@OUTBUF,LENG |
| �@�@�@�@�@�@RPOP |
| �@�@�@�@�@�@RET |
| �@�@OUTBUF�@DS�@�@ 84 |
| �@�@OUTLEN�@DC�@�@ 84 |
| �@�@LENG�@�@DS�@�@ 1 |
| �@�@�@�@�@�@END |
| �@�@HEXCNV�@START |
| �@�@�@�@�@�@LAD�@�@GR6,0�@�@�@�@�@; �V�t�g�ʂ� 0 �ɏ����ݒ� |
| �@�@LP�@�@�@LD�@�@ GR7,GR5 |
| �@�@�@�@�@�@SLL�@�@GR7,0,GR6�@�@�@; �ϊ��Ώۂ���� 4 �r�b�g�ɐݒ� |
| �@�@�@�@�@ �@ |
�@�@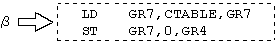 |
| �@�@�@�@�@�@LD�@�@ GR7,CTABLE,GR7�@ |
| �@�@�@�@�@�@ST�@�@ GR7,0,GR4 |
| �@�@�@�@�@�@LAD�@�@GR4,1,GR4 |
| �@�@�@�@�@�@LAD�@�@GR6,4,GR6 |
| �@�@�@�@�@�@CPA�@�@GR6,=16�@�@�@�@; 1 �ꕪ�� 16 �i�ϊ������H |
| �@�@�@�@�@�@JMI�@�@LP |
| �@�@�@�@�@�@RET |
| �@�@CTABLE�@DC�@�@ '0123456789ABCDEF' |
| �@�@�@�@�@�@END |
�@
| �ݖ�P |
�@�v���O�������� �ɓ���鐳�����������C�Q�̒�����I�ׁB
|
a �Ɋւ���Q
�A�@JMI FIN�@�@�@�@�C�@JMI LP1�@�@�@�@�E�@JPL FIN
�G�@JPL LP1�@�@�@�@�I�@JZE FIN�@�@�@�@�J�@JZE LP1
b �Ɋւ���Q
�A�@ADDL GR4,GR5�@�@�@�@�C�@LAD GR4,84,GR5�@�@�@�@�E�@LD GR4,84,GR5
�G�@SUBL GR4,GR5
c �Ɋւ���Q
�A�@AND GR7,=#000F�@�@�@�@�C�@AND GR7,=#F000�@�@�@�@�E�@OR GR7,=#000F
�G�@OR GR7,=#F000�@�@�@�@�I�@SRL GR7,12�@�@�@�@�J�@SRL GR7,13
|
| �@ |
| �ݖ�Q |
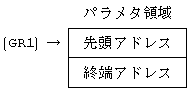
�@�p�����^�̈�ɔ͈͂̐擪�A�h���X�ƏI�[�A�h���X���i�[���C�p�����^�̈�̐擪�A�h���X�� GR1 �ɐݒ肵�ČĂяo���悤�� HEXDUMP
��ύX���邱�Ƃɂ����B�v���O�������� �� �̈ʒu�ɑ}�����ׂ����ߗ�Ƃ��Đ������������C�Q�̒�����I�ׁB
|
| �Q |
|
�A�@�@ |
| LD GR1,0,GR1�@�@�@�@ |
| LD GR2,1,GR1�@ �@ |
|
|
�C�@ |
| LD GR1,1,GR1�@�@�@�@ |
| LD GR2,2,GR1 |
|
|
�E�@ |
| LD GR2,1,GR1 |
| LD GR1,0,GR1 |
|
|
�G�@ |
| LD GR2,2,GR1�@ |
| LD GR1,1,GR1�@ |
|
|
|
| �ݖ�R |
�@�v���O�������� �� �����̖��ߗ�Œu�������邱�Ƃɂ����B�ύX�O�Ɠ������ʂ邽�߂ɖ��ߗ� �ɓ���鐳�����������C�Q�̒�����I�ׁB
�@�@ �@ �@CPA GR7,=9
�@�@�@�@�@ JPL AF
�@�@�@ �@�@LAD GR7,#0030,GR7 ; ���� 0 �̕����R�[�h�����Z
�@�@�@�@�@ JUMP CONT
�@�@AF�@�@�@
�@�@�@�@�@ CONT ST GR7,0,GR4 |
|
|
| �� |
|
|
�A�@�@ |
LAD GR7,#0031,GR7�@ |
|
�C�@ |
LAD GR7,#0037,GR7 |
|
�E�@ |
LAD GR7,#0038,GR7�@ |
|
�G�@ |
LAD GR7,#0039,GR7 |
|
�I |
LAD GR7,#0041,GR7 |
|
|
| �@�@�@ �@�@�@�@�߂� |